UX Design: Between Subjects vs Within Subjects
Table Of Content
In contrast, there are no variations in individual differences between conditions in a within-subjects design because the same individuals participate in all conditions. In experiments, a different independent variable treatment or manipulation is used in each condition to assess whether there is a cause-and-effect relationship with a dependent variable. The key difference between observational studies and experiments is that, done correctly, an observational study will never influence the responses or behaviours of participants. Experimental designs will have a treatment condition applied to at least a portion of participants.
Two Ways to Plan Your Study
They’ll also notice your most common mistakes, and give you personal feedback to improve your writing in English. Please note that the shorter your deadline is, the lower the chance that your previous editor is not available. We try our best to ensure that the same editor checks all the different sections of your document. When you upload a new file, our system recognizes you as a returning customer, and we immediately contact the editor who helped you before. Explanatory research explains the causes and effects of an already widely researched question. There are many different types of inductive reasoning that people use formally or informally.
Carryover effects
Comparable level of aggression between patients with behavioural addiction and healthy subjects Translational ... - Nature.com
Comparable level of aggression between patients with behavioural addiction and healthy subjects Translational ....
Posted: Mon, 05 Jul 2021 07:00:00 GMT [source]
The value of a dependent variable depends on an independent variable, so a variable cannot be both independent and dependent at the same time. A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. Longitudinal studies and cross-sectional studies are two different types of research design. In a cross-sectional study you collect data from a population at a specific point in time; in a longitudinal study you repeatedly collect data from the same sample over an extended period of time.
Extraneous Variable
Each treatment ideally appears equally often in each position (e.g., third) of the sequence. The goal was to generate the highest quality data possible, in a reasonable amount of time. In Study 1, Car Company A provided four systems to test, each system taking roughly an hour to evaluate. Because of this, a between-subjects design made the most sense; each participant interacted with just one system.
Individual differences may threaten validity
This allows researchers to directly compare the responses of each individual, rather than relying on group averages as in between-subjects designs. So far, we have discussed an approach to within-subjects designs in which participants are tested in one condition at a time. There is another approach, however, that is often used when participants make multiple responses in each condition.
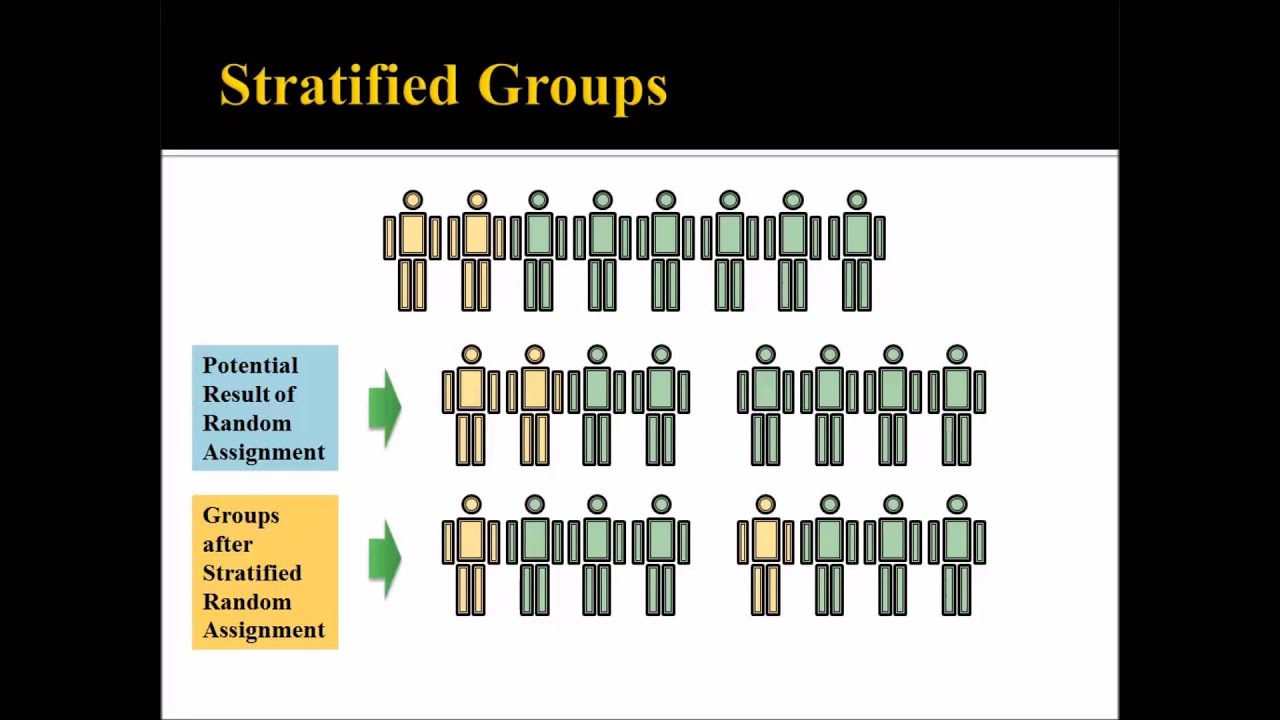
Once you select your participants, you will need to determine how to assign your participants to each condition. Random assignment is a common method, ensuring that every participant has the same chance of being assigned to any group. This method helps ensure that any differences between groups are due to the independent variable, not pre-existing differences among participants. Between-subjects and within-subjects designs are two different methods for researchers to assign test participants to different treatments. For example, there would be three groups of subjects, each receiving one of the three treatment conditions.
Any type of user research that involves more than a single test condition must determine whether to be between-subjects or within-subjects. When deciding the design of your experiments, it's important to understand the strengths and weaknesses of the options available to you. When it comes time to choose the design that meets your study’s needs, a good rule of thumb is to determine whether the differences you're looking to study are between subjects or within subjects. Researchers often find themselves choosing from a between-subjects design and a within-subjects one. These two options are opposites in many ways, and making the correct choice means understanding the unique differences between the two, as well as their strengths and weaknesses.

Within-subjects designs have more statistical power due to the lack of variation between the individuals in the study because participants are compared to themselves. In a between-subjects design, researchers will assign each subject to only one treatment condition. In contrast, in a within-subjects design, researchers will test the same participants repeatedly across all conditions.

We could do this because our participant pool was large; we only needed licensed drivers (which nearly everyone is). Implementing a between-subjects design also enabled us to run multiple sessions at once, speeding things up. Had we implemented a within-subjects design, each participant would have had to endure roughly four hours of tasks and interviewing. Four hours straight of anything isn’t fun, and when participants are fatigued, data quality can suffer. Here are the essentials, in a between-subjects design, two or more subject groups experience their own unique condition. If we wanted to compare the desirability of apples to oranges, one group of participants would eat an apple and the other group would eat an orange.
Between-subjects studies require at least twice as many participants as a within-subject design, which also means twice the cost and resources. The differences between the two groups are then compared to a control group that does not receive any treatment. The groups that undergo a treatment or condition are typically called the experimental groups. In within-subjects studies, the participants are compared to one another, so there is no control group. The data comparison occurs within the group of study participants, and each participant serves as their own baseline. Data collection can take a long time since each participant is given multiple treatments.
On the other hand, convenience sampling involves stopping people at random, which means that not everyone has an equal chance of being selected depending on the place, time, or day you are collecting your data. Because not every member of the target population has an equal chance of being recruited into the sample, selection in snowball sampling is non-random. On the other hand, content validity assesses how well the test represents all aspects of the construct. If some aspects are missing or irrelevant parts are included, the test has low content validity. Face validity and content validity are similar in that they both evaluate how suitable the content of a test is. The difference is that face validity is subjective, and assesses content at surface level.
The group is chosen due to predefined demographic traits, and the questions are designed to shed light on a topic of interest. As a rule of thumb, questions related to thoughts, beliefs, and feelings work well in focus groups. Take your time formulating strong questions, paying special attention to phrasing.
In such an experiment, you will not require an trial or control group as all subjects will be part of the same procedure. This study design is coined “within-subjects” because conditions are compared within the same group of participants. On the other hand, a between-subjects design is the opposite of a within-subjects design where the differences in conditions occur between the groups of subjects. There are many time-related threats to internal validity that only apply to within-subjects design because it’s hard to control the effects of time on the outcomes of the study. Because researchers can’t prevent the effects of time, longitudinal studies usually study correlations between time and other (dependent) variables.
In research on psychotherapy effectiveness, the placebo might involve going to a psychotherapist and talking in an unstructured way about one’s problems. This is what is shown by a comparison of the two outer bars in Figure 6.2 “Hypothetical Results From a Study Including Treatment, No-Treatment, and Placebo Conditions”. Even without such an obvious bias as your personal preferences, it’s easy to get randomization wrong.
Another difference is that a within-subjects design does not feature control groups. Instead, subjects are verified beforehand and after the application of the independent variable treatments. Between-subjects designs usually have a control group (e.g., no treatment) and an experimental group, or multiple groups that differ on a variable (e.g., gender, ethnicity, test score etc). An independent variable is the variable you manipulate, control, or vary in an experimental study to explore its effects. It’s called ‘independent’ because it’s not influenced by any other variables in the study.
Researchers will manipulate an independent variable to create at least two treatment conditions and then compare the measures of the dependent variable between groups. There are no control groups in within-subjects designs because participants are tested before and after independent variable treatments. The pretest is similar to a control condition where no independent variable treatment is given yet, while the posttest takes place after all treatments are administered. Random assignment is not guaranteed to control all extraneous variables across conditions. One is that random assignment works better than one might expect, especially for large samples.


Comments
Post a Comment